用 Obsidian + Claude Code 搭建一个越来越聪明的 AI 知识库
卡帕西上周在 X 上发了一篇帖子,讲他最近用 LLM 搭建个人知识库的方法。
发出来之后直接火了,浏览量破千万。
核心思路是:不再自己整理笔记,让 AI 帮你读完所有资料,自动构建一个结构化的 Wiki 知识网络。你只需要负责两件事——喂资料,提问题。
我用 Obsidian + Claude Code 把这套流程完整跑了一遍,这篇文章记录整个搭建过程。
先说它解决了什么问题
你用过 RAG 类的 AI 知识库产品吗?就是那种"上传文章然后问 AI"的工具。
它的底层是向量检索:把文章切成片段,存成向量,你提问时检索最相关的几段,拿这几段拼一个答案。
问题在于——每次提问都是从零开始。上次的回答对这次没有任何积累,AI 也没有真正理解这批资料之间的关联。
卡帕西的方法不一样。

三层结构
整套系统只有三层:
第一层:原始资料(raw/)
你收集的所有原始内容放这里——文章、论文、YouTube 视频字幕、截图。只有你能往里加,AI 不修改这层。
第二层:Wiki 知识网络(wiki/)
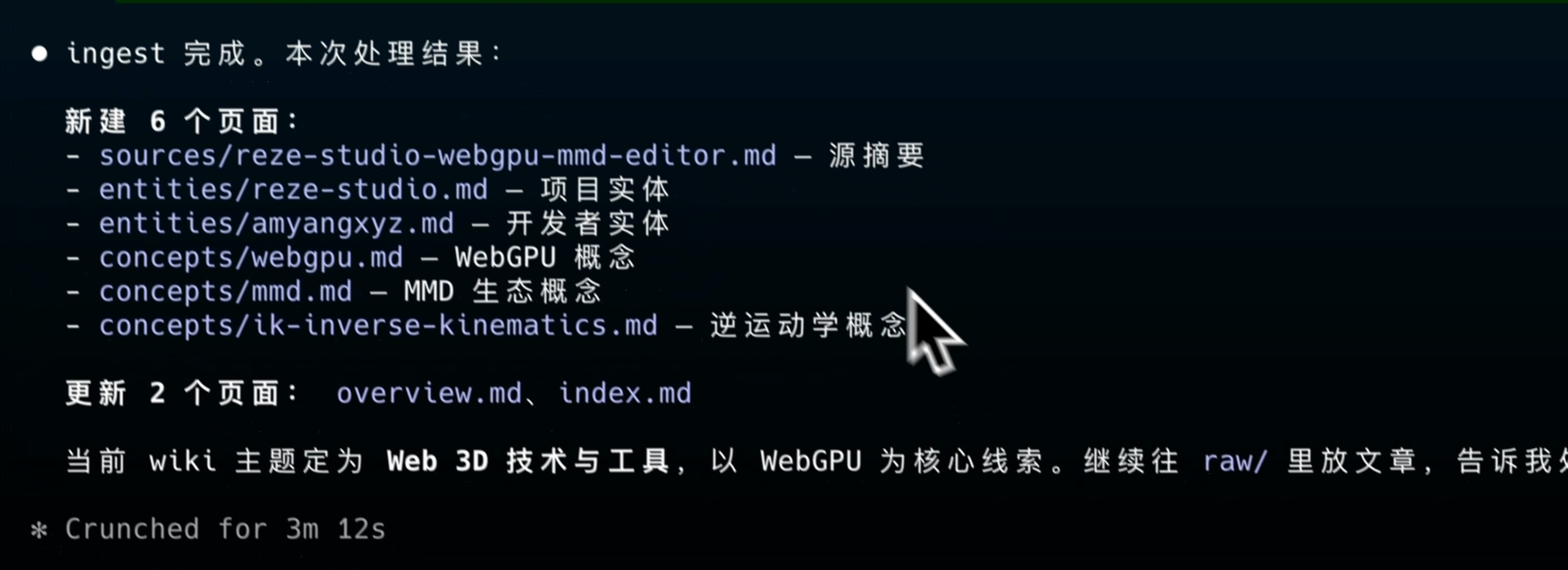
完全由 AI 维护的结构化 Markdown 文件网络。每当你加入新资料,AI 读取、提炼,把新内容整合进来:建概念页、写文章摘要、建立交叉引用。
第三层:规则文档(CLAUDE.md)
一个配置文件,告诉 AI 怎么工作——目录结构、命名规则、摄入流程、健康检查怎么做。这个 AI 自己来生成和维护。

第一步:建仓库结构
下载wiki文件
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f (opens in a new tab)
 在 Obsidian 里新建一个 vault,然后在这个目录下打开 Claude Code。
在 Obsidian 里新建一个 vault,然后在这个目录下打开 Claude Code。
把下面这段需求发给 Claude Code:
帮我按照 Karpathy 的 LLM wiki 方法搭建一个知识库结构,它不只建了目录,CLAUDE.md 里会自己写好完整的工作规则。这个文件就是 AI 的"说明书",以后每次开新对话,它都会读这个文件,知道怎么工作。
第二步:录入原始资料
推荐装一个 Chrome 插件:Obsidian Web Clipper(Obsidian 官方出的)。
https://chromewebstore.google.com/detail/obsidian-web-clipper/cnjifjpddelmedmihgijeibhnjfabmlf (opens in a new tab)
 打开任何一篇网页文章,点一下,直接以 Markdown 格式保存到本地 vault,图片链接也一并保存。YouTube 视频也支持,会自动提取字幕。
打开任何一篇网页文章,点一下,直接以 Markdown 格式保存到本地 vault,图片链接也一并保存。YouTube 视频也支持,会自动提取字幕。
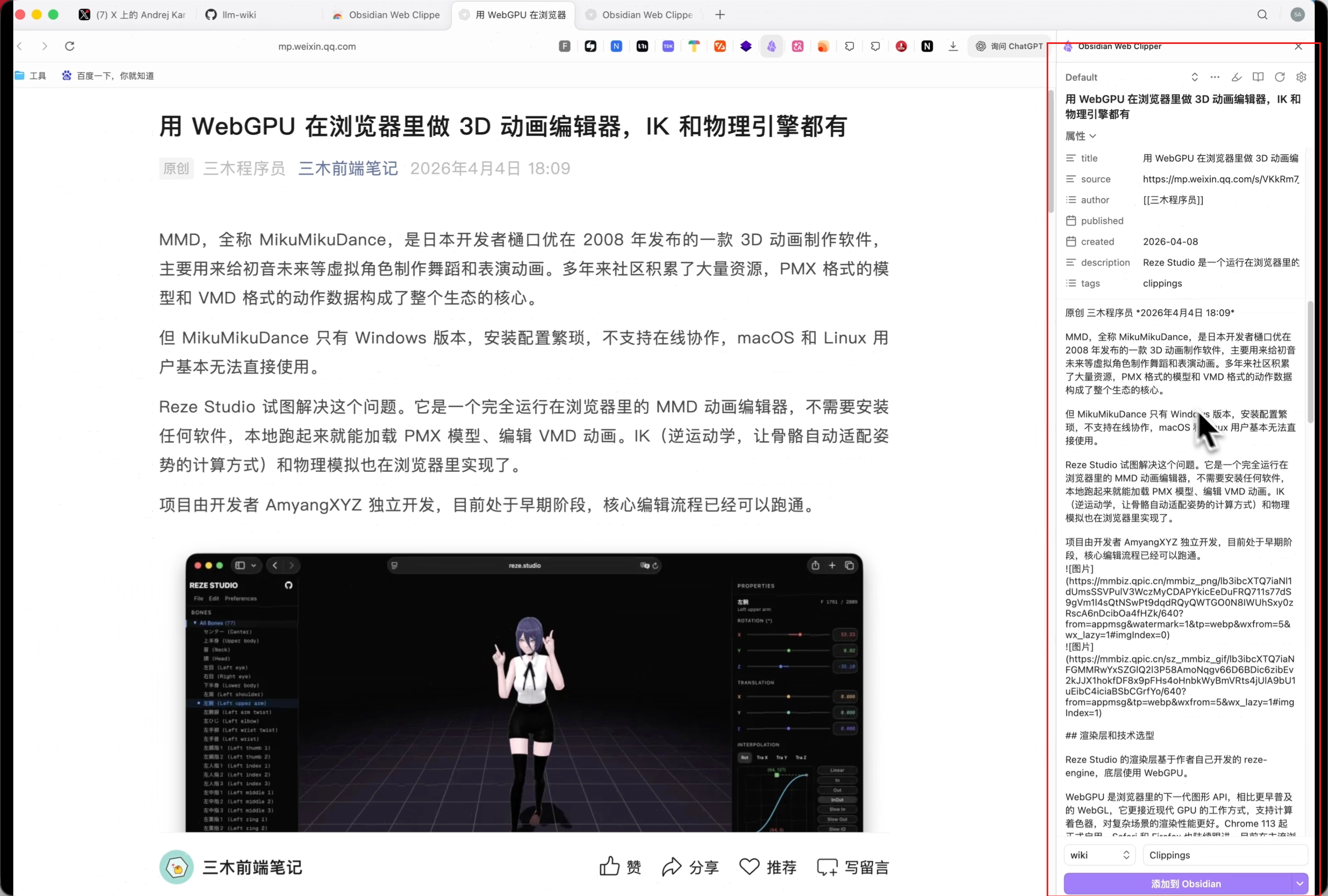
我这里准备了文章,保存到 raw/ 目录。
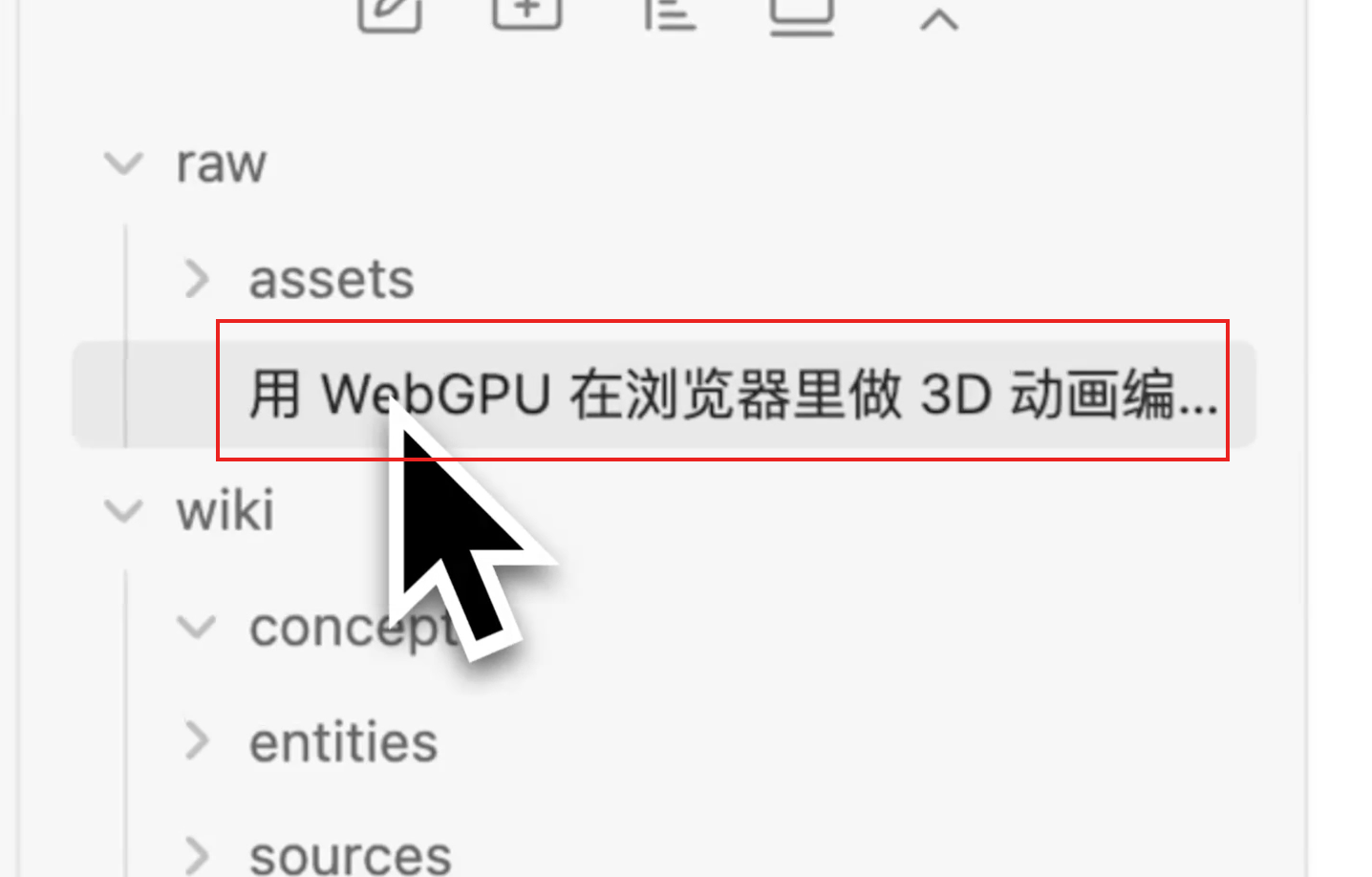
第三步:摄入——让 AI 消化资料
告诉 Claude Code 有新内容进来了:
raw/ 目录下新增了几篇文章,请按照 CLAUDE.md 的摄入流程处理。
AI 会逐篇读取,提炼核心概念
适合什么场景
最后说一个很多人搞错的地方。
卡帕西这套方法不适合做个人日常笔记,原因有三:
- 碎片内容没有提炼价值,几十个字的想法不需要建概念页
- 个人笔记会频繁修改,原始资料一改,摘要和网络都要跟着变,成本高
- 内容太杂时 AI 没法建立有意义的关联——同一个知识库里放 Three.js 和红楼梦,它们之间没有连线
最适合的场景:
- 学一个新技术方向,需要阅读大量资料
- 做某个专题的深度研究
- 有固定的高质量信息来源(博客、论文、技术文档)
你有越多同一主题的高质量资料,这套系统就越有价值。