3D渲染也卡顿?Apple ICLR论文教你用潜表示解决视角相关反射
你在Three.js或WebGL里渲染3D模型时,是不是碰到过这个痛点:加载个高保真模型,整个页面就卡顿了,更别说镜面反射、菲涅尔效应这些视角相关的光学效果。最糟糕的是,质量和性能永远是二选一的——要么模型清晰但很卡,要么流畅运行但看起来很假。
Apple研究团队在ICLR 2026发表了一篇新论文LiTo(Surface Light Field Tokenization),给出了一个完全不同的思路:不用提前烘焙纹理,用紧凑的潜向量表示整个表面光场,一个编码就能同时记录几何和视角相关反射。换句话说,用1/10的数据量,却能做出更真实的3D效果。
为什么现在的3D重建都做不好视角相关反射
这个问题的根源在于,现有的3D重建方法陷入了一个难以解脱的困境。传统方法要么只关注几何(如PointFlow、ShapeToken),要么只预测漫反射颜色,根本无法同时处理这两者。结果就是镜面反射位置总是固定的,菲涅尔效应表现不足,高光位置在复杂光照下完全错误。

看看竞争对手怎样失败的。3DTopoXL虽然尝试编码材质属性,但需要提前准备一堆前期处理,最终看起来还是假得很。TRELLIS是现在最快的方法,但它依赖粗几何先验,对视角相关细节的编码能力严重不足——用金属茶罐和苹果测试时,TRELLIS生成的高光位置完全错地方了。
从单张图像生成3D这个问题更糟。NeRF需要30分钟到2小时训练,3D GAN虽然快但质量参差,结果化形。没有一个方法能同时兼顾速度、质量和光影准确性。
什么是表面光场令牌化
这个概念听起来复杂,但其实很直观。想象你拿着相机在物体周围走一圈,从每个位置、每个角度都拍一张照。把所有这些照片合在一起,就是表面光场——它记录了物体表面上每个点从各个观看方向看到的光线信息。
这个5D函数既包含了几何(物体的轮廓和形状),也包含了视角相关的外观(镜面反射、菲涅尔效应)。论文的关键创新就是把这个复杂的5D函数用一组紧凑的潜向量来编码。
关键数字:论文用8192个潜向量,每个32维,总数据量只有32K个数值。对比传统的高分辨率纹理需要几十MB,这简直是压缩怪物。而更重要的是,这些数据不是简单的颜色值,而是表面光场的本质特征,天生包含了视角相关的光学信息。
LiTo的系统架构
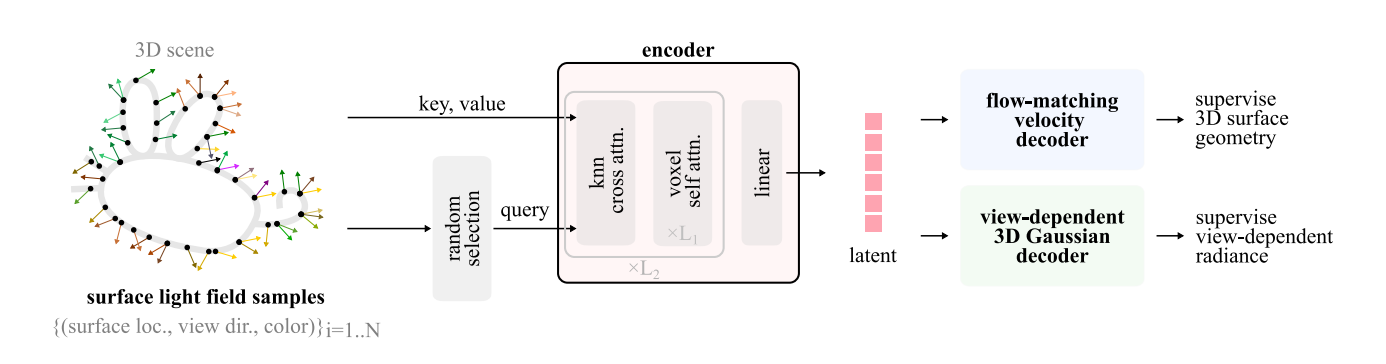
LiTo分三层构建。第一层是编码器,输入150张RGB-depth图像。编码器首先从这些多视图中稠密采样表面光场,然后用一个基于Perceiver IO的编码器来融合几何和外观信息。这里有个巧妙的设计叫3D Patchification——不是在2D像素网格上做注意力机制,而是直接在3D表面上进行K-最近邻分组。这样处理非欧几里得的表面几何自然得多。编码器输出8192个潜向量,维度32。
为什么这样做?因为传统的体素网格或SDF对复杂拓扑处理不好,而LiTo用点云加注意力,天然支持任意拓扑。
第二层是监督学习。编码后的潜向量需要被教导什么是几何、什么是外观。几何这边用Flow Matching模型来确保解码的点云与地面真值对齐。外观这边用3D高斯溅射解码器,每个潜向量解码成高阶球面调和函数(degree 3),表示视角相关的反射。
最妙的地方在于,这些监督信号都来自同一份RGB-depth数据,不需要额外的法线标签或材质标签。模型自动学会什么时候是漫反射、什么时候是镜面高光。
第三层是生成模型。为了从单张图像生成3D,论文训练了一个Latent Flow Matching模型。输入是单张图像(用DINO v2编码)加位置编码,输出整个潜向量集合。架构是标准的扩散变换器,623M参数。关键是它不像TRELLIS那样依赖粗几何先验,直接从图像推断完整的3D,而因为潜表示本身包含视角相关信息,生成的模型天生就有正确的反射。
数字会说话
在Toys4k数据集上的重建质量对比:
| 方法 | PSNR | SSIM | LPIPS |
|---|---|---|---|
| TRELLIS | 27.57 | 0.941 | 0.090 |
| LiTo | 34.16 | 0.985 | 0.023 |
PSNR提升6.6dB意味着明显的视觉质量改进。LPIPS从0.090降到0.023,说明LiTo的渲染和地面真值的感知距离减少了75%。SSIM提升到0.985几乎完美。
但数字只是表面。真正的差异在视觉上——看看茶罐,LiTo的镜面反射高光位置与地面真值吻合,而竞争方法都错了。看看苹果,边缘的菲涅尔效应(视角相关的粉红色光泽)清晰可见,其他方法根本没有。

单图到3D生成的质量对比更惊人。论文用KID指标衡量生成质量,LiTo的FID从TRELLIS的12.84提升到6.219(降低52%),KID从0.088改进到0.009(降低90%)。这不只是数字,看看效果图就知道。
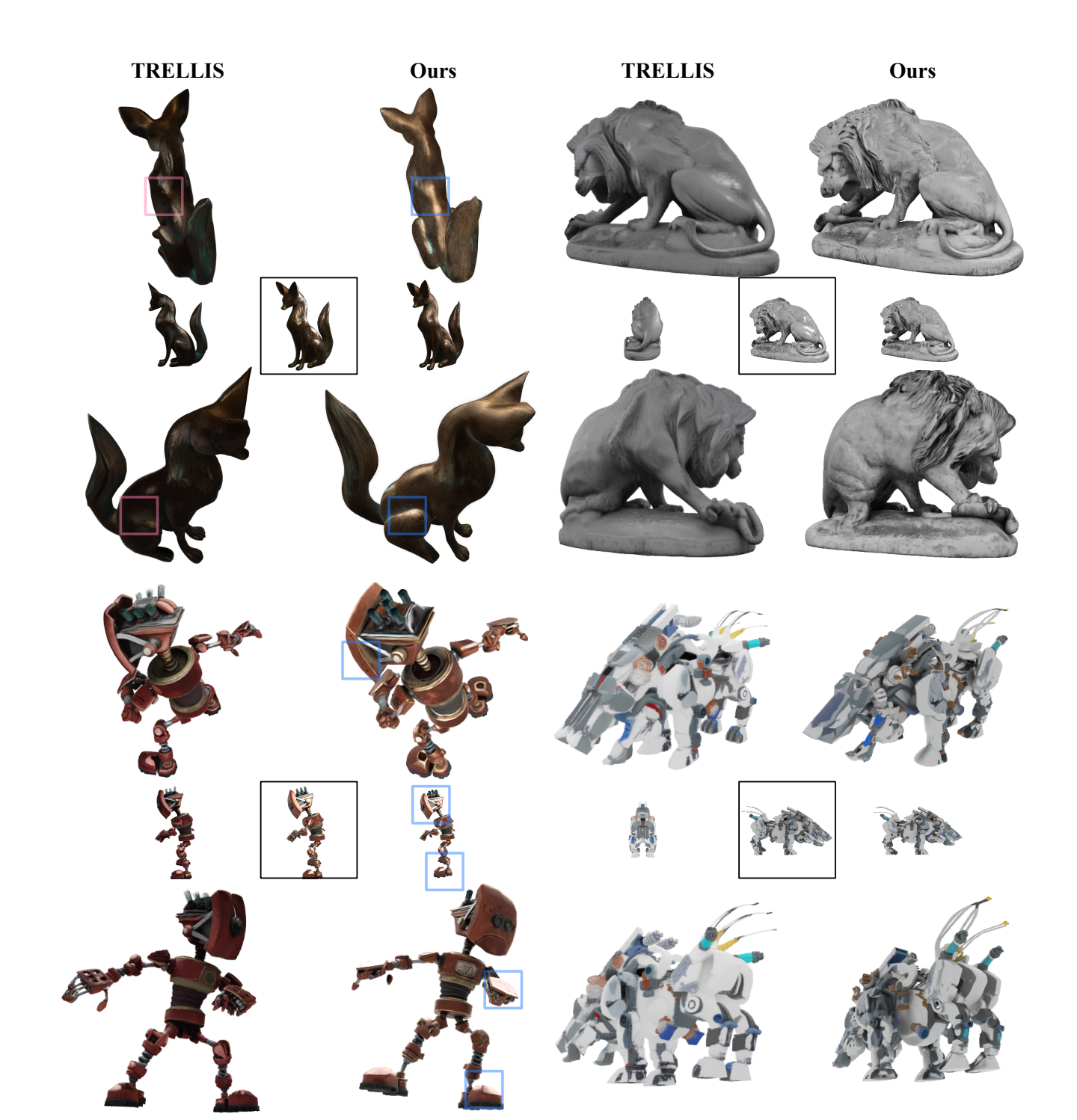
兔子的毛发高光,LiTo更逼真。牛的几何细节和材质感,LiTo清晰得多。复杂的战斗机器人,LiTo保留了所有细节。金属飞行器,LiTo的反射方向正确。
最关键的是忠实度。LiTo生成的模型在输入视角的渲染与输入图像高度一致,而TRELLIS生成的颜色和材质与输入明显不符。这意味着你拍的照片长什么样,生成的3D模型就长什么样。

对Web 3D的真实意义
现在Web 3D开发者面临一个现实的困境。从图像到3D的流程太长:设计师出效果图,建模师建模要1-2周,材质师做贴图,渲染优化。如果要准确的镜面反射,还要额外做球面调和函数映射。
烘焙的纹理是静态的,光照一变就得重新烘焙。实时PBR虽然能动态响应光照,但在移动端吃性能。金属、玻璃、皮肤这些视角相关很强的材质最难渲染得逼真。
LiTo改变了什么?从单张设计图,它能直接生成完整的3D——动物有几何加毛发高光,人物角色有衣服和皮肤的材质分离,机器有正确变化的镜面反射。这意味着设计流程从"设计图→手工建模→贴图→调参地狱"变成"设计图→LiTo生成→Three.js直接用"。
对产品可视化和AR试穿,这意味着用户上传产品照片,系统自动生成可交互的3D模型,在AR中从各个角度看都有正确的镜面反射响应光照,而不是烘焙的假反射。
对游戏开发,这意味着进入了UGC(用户生成内容)时代。用户拍照,AI生成可用资产,生成的资产自带正确的材质反射,直接能用。
因为潜向量是连续向量空间,你还可以做两个模型之间的平滑插值,调整某个维度实时改变模型的镜面性,甚至在向量空间直接做风格迁移。论文虽然没展示这些demo,但这是潜表示的天然能力。
不要忽视的局限
LiTo不是银弹。训练时需要150张高质量的RGB-depth图像球面分布采样,这要求专业的深度传感或结构光扫描。生成时虽然只需单张图像,但输入要有清晰的物体主体,背景杂乱会降低质量。
论文的实验数据都是单一物体,相对简单的拓扑。物体间的交互、薄壳结构、液体这样的非刚体没有测试。
生成速度未明确说明,但Diffusion Transformer需要多步去噪,想必不会快。部署成本也高——编码器59.2M参数、生成模型623M、解码器77.3M,总共759.5M参数,移动端跑不了。对比TRELLIS参数更少速度更快。
LiTo用球面调和函数degree 3表示视角相关反射,在大多数情况足够,但拉丝金属这样的非各向同性材质可能表现不足,细小划痕的高频反射也可能丢失。半透明皮肤这样需要考虑体积效应的材质没有覆盖。
这个方向意味着什么
潜表示的威力首次得到验证。曾经我们认为"要么用几何加纹理,要么用神经隐函数",LiTo证明了用紧凑向量集合表示整个表面光场反而能同时优化几何和外观。这个思路可能会在体积渲染、动作捕捉等其他领域得到应用。
视角相关反射不再是性能和质量的tradeoff。烘焙浪费存储,实时计算浪费性能,LiTo让它成为潜表示的固有属性。解码时自动得到正确反射,零额外成本。
单图生成3D的问题有了真正的解决方案。NeRF太慢,GAN质量差,LiTo用Flow Matching兼顾了速度、质量和光影准确性。这预示着未来3D生成模型都可能基于类似的潜表示。
短期内(1-2年),Blender和Maya可能集成类似的生成模块,Three.js生态会出现WebGPU/WASM版本的实现,AR/VR应用会用到用户照片实时生成的3D模型。中期(3-5年),"3D资产库"的概念可能被"AI参数化生成"取代,美术工作流从手工建模变成AI辅助的参数编辑,UGC时代普通用户也能生成专业质量的3D内容。
如果你要在自己项目中应用类似思路,短期用Three.js加高分辨率纹理或Gaussian Splatting。中期关注开源实现,等待Apple或社区开源LiTo推理代码。长期如果有特定领域需求,可以自己训练潜表示模型,用更小的参数量针对Web端优化。
立即获取和跟进
论文和项目主页:
- 📄 论文:https://arxiv.org/abs/2603.11047 (opens in a new tab)
- 🔬 项目主页https://apple.github.io/ml-lit (opens in a new tab)
- 🏫 Apple ML Research:https://machinelearning.apple.com/research/lito (opens in a new tab)
- 💬 OpenReview讨论:https://openreview.net/forum?id=TVP0p4f2Su (opens in a new tab)
代码还没开源,但从Apple的历史看,通常会在论文发表后逐步开源。关注上面这些链接,有更新第一时间就能知道。
相关的开源项目值得现在就开始用:Gaussian Splatting是另一种紧凑3D表示,已有成熟实现;NeuralField系列是Apple开源的神经表示方法;Instant-NGP是NVIDIA的快速NeRF实现。
最值得关注的是接下来几个月的WebGPU优化。如果Apple开源代码,怎样在Web端高效运行潜表示的解码?会不会有Three.js插件支持LiTo格式导入?iOS/Android如何快速生成和渲染LiTo模型?这些都是接下来的看点。