WebGPU 做烟雾云层渲染,64MB 数据压到 28MB 是怎么做到的
体积数据(Volumetric Data)在三维可视化中用于表示烟雾、云层、火焰、医学 CT 扫描等"非实体"的三维对象。与网格模型不同,这类数据用三维格子里每个点的密度值来描述空间分布,数据量通常很大,且大部分格子是空的。
在这一领域,有一条比较清晰的技术传承关系:OpenVDB 是工业标准(由 DreamWorks 开源,Houdini、Blender 等主流三维软件均支持),NanoVDB 是 NVIDIA 在此基础上推出的 GPU 加速版本,去掉了不适合 GPU 的部分,支持在 GPU 上直接读取和处理体积数据。
但对于 WebGPU 这个浏览器端 GPU API 来说,NanoVDB 并没有针对性的适配。它的数据结构是为通用 GPU 设计的,用在 WebGPU 上时,文件体积和内存布局都存在额外开销。
PicoVDB 是 GitHub 用户 emcfarlane 开发的一个开源项目,定位是「专为 WebGPU 实时渲染优化的紧凑稀疏体积数据格式」。它以 NanoVDB 文件作为输入,转换成自定义的 .pvdb 格式,并提供配套的 WGSL 着色器库和 TypeScript 加载器,方便在 WebGPU 着色器管线中直接使用。
三处压缩改动
PicoVDB 的体积缩减来自三项具体改动,每一项都对应 NanoVDB 在 WebGPU 上的一个具体问题。
位掩码排名查询(Bit Mask Rank Query Compression)
体积数据通常是高度稀疏的——大多数格子是空的,只有少量格子存储了实际数值。NanoVDB 用位掩码标记哪些格子是活跃的,但在遍历时需要额外存储每个活跃格子的偏移位置,以便快速定位。PicoVDB 改用「排名查询」方式,通过对位掩码直接计算,就能推算出任意活跃格子的存储位置,不再需要单独保存偏移数组。这样消除了大量非活跃格子占用的冗余存储。
32 位偏移索引替代 64 位指针
NanoVDB 内部用 64 位指针在数据树的各层级之间(根节点、中间节点、叶节点)进行跳转。PicoVDB 改用 32 位偏移索引,存储空间直接减半,同时更符合 GPU 的原生数据宽度,减少在 GPU 寄存器上的无效填充。这一改动将活跃体素上限设定在约 40 亿个(2 的 32 次方),对大多数实时渲染场景足够使用。
GPU 内存对齐结构
GPU 在读取数据时对内存对齐有明确要求,不对齐的结构会引入额外填充字节(padding),造成实际占用内存大于有效数据。PicoVDB 在设计数据结构时专门针对 GPU cache line 做了对齐处理,减少内存读取时的浪费,也有助于提高缓存命中率。
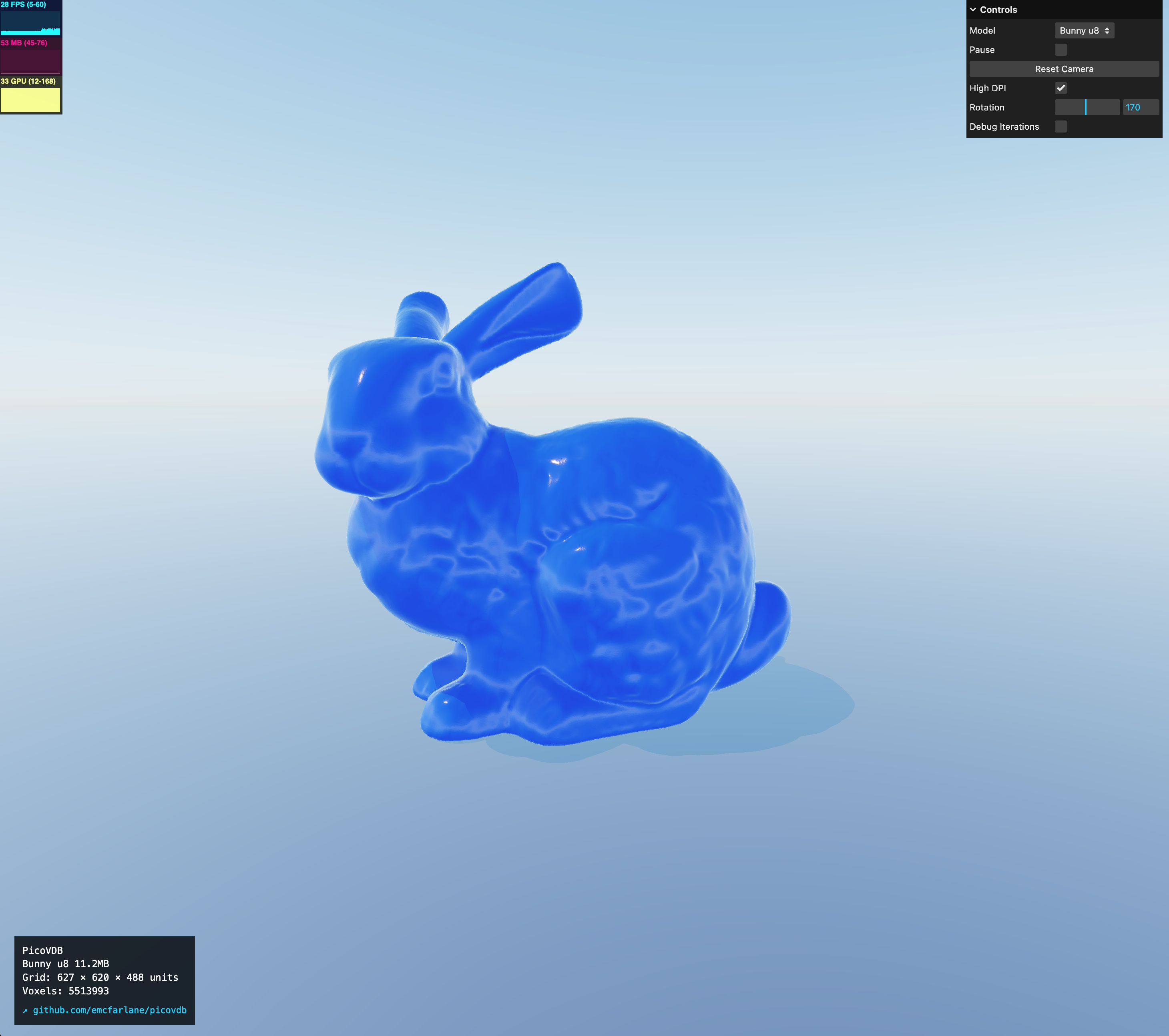
以常用测试数据集 Stanford Bunny 为例,NanoVDB 格式下文件体积为 64MB,PicoVDB 格式下为 28MB,压缩幅度超过 56%。
仓库包含的三个部分
| 文件 | 语言 | 用途 |
|---|---|---|
picovdb.wgsl | WGSL | WebGPU 着色器库,包含体积遍历所需的函数 |
picovdb.ts | TypeScript | .pvdb 文件加载器,在 JavaScript 侧解析数据 |
src/main.zig | Zig | 命令行转换工具,将 .nvdb 转换为 .pvdb |
三个部分分别对应数据管线的不同位置:转换工具处理离线转换,TypeScript 加载器负责在页面中读取数据并提交给 GPU,WGSL 着色器库处理 GPU 侧的体积遍历逻辑。
安装与文件转换
使用 PicoVDB 的起点是一份 NanoVDB 格式的源文件(.nvdb)。可以从 OpenVDB 官方数据集下载,也可以通过 Houdini、Blender 等支持 OpenVDB 导出的工具自行生成后转换为 NanoVDB 格式。
前提条件:需要安装 Zig (opens in a new tab)(用于编译 Zig 语言编写的转换工具)。
构建转换工具:
zig build执行格式转换:
./zig-out/bin/picovdb input.nvdb output.pvdb将 input.nvdb 替换为实际文件路径,运行后生成 .pvdb 文件,供 Web 端加载使用。
在 WebGPU 着色器中集成
体积数据在 WebGPU 侧被拆分为五个层级,分别绑定到不同的存储缓冲区。在 WGSL 着色器中需要声明以下绑定:
@group(0) @binding(2) var<storage> picovdb_grids: array<PicoVDBGrid>;
@group(0) @binding(3) var<storage> picovdb_roots: array<PicoVDBRoot>;
@group(0) @binding(4) var<storage> picovdb_uppers: array<PicoVDBUpper>;
@group(0) @binding(5) var<storage> picovdb_lowers: array<PicoVDBLower>;
@group(0) @binding(6) var<storage> picovdb_leaves: array<PicoVDBLeaf>;
@group(0) @binding(7) var<storage> picovdb_buffer: array<u32>;五组绑定对应体积数据树结构的各个层级:根节点(root)、上层中间节点(upper)、下层中间节点(lower)和叶节点(leaf),加上存储实际数值的原始缓冲区。
绑定完成后,可调用 WGSL 着色器库提供的 picovdbHDDAZeroCrossing 函数对体积进行层次化光线步进(HDDA,Hierarchical DDA)采样。HDDA 的优点在于能跳过空白区域,不需要对每一段射线等距采样,在稀疏数据上效率明显优于朴素的光线步进。
项目提供了在线演示,可以在这里直接看到实际渲染效果:https://emcfarlane.github.io/picovdb/demo/ (opens in a new tab)
写在最后
PicoVDB 解决的是一个比较具体的工程问题:把 NanoVDB 体积数据放到 WebGPU 上用,如何减少文件大小和内存开销。它不是独立的体积数据解决方案,而是依附在现有的 OpenVDB/NanoVDB 生态上,专注于「NanoVDB → WebGPU 可用格式」这一段转换。
如果你的项目涉及在浏览器端做烟雾、云层等实时体积渲染,且数据来源已经是或可以导出为 NanoVDB 格式,PicoVDB 提供的压缩方案和 WebGPU 原生集成值得参考。需要注意的是,项目目前处于活跃开发阶段,README 中明确说明格式和 API 仍可能变化,直接用于生产环境需要评估稳定性风险。
GitHub 地址:https://github.com/emcfarlane/picovdb (opens in a new tab)